Khi tìm hiểu trí tuệ nhân tạo, bạn sẽ sớm bắt gặp thuật ngữ deep learning là gì, cũng như lý do vì sao lĩnh vực này đặc biệt cần đến GPU. Trong vài năm gần đây, deep learning đã bùng nổ, tạo ra những bước tiến lớn trong xử lý ảnh, ngôn ngữ, xe tự lái. Nhưng tại sao lại không dùng CPU như truyền thống, mà phải đầu tư những dàn GPU mạnh mẽ? Bài viết này giải thích rõ cho bạn, từ khái niệm gốc rễ đến dấu ấn thực tiễn và cả những điểm thường bị bỏ qua trong lựa chọn hạ tầng AI.
Deep learning là gì? Bản chất và ứng dụng thực tế
Deep learning (học sâu) là một nhánh trong machine learning. Thay vì lập trình bộ luật cố định, deep learning sử dụng mạng neuron nhiều lớp (deep neural networks) để phát hiện và mô hình hoá các đặc trưng phức tạp từ dữ liệu lớn. Mỗi “layer” (lớp) học ra một mức trừu tượng cao hơn, ví dụ từ cạnh ảnh đến vật thể rồi nhận diện khuôn mặt…
- Dữ liệu lớn: Deep learning chỉ thực sự tỏ ra vượt trội khi dữ liệu đủ nhiều, ví dụ hàng triệu bức ảnh, văn bản.
- Học đặc trưng tự động: Không cần chuyên gia trích xuất tính năng thủ công. Hệ thống tự tìm ra các feature phù hợp khi huấn luyện.
- Ứng dụng thực tế: Deep learning tạo dấu ấn ở nhận diện tiếng nói, dịch máy, xe tự lái, tổng hợp hình ảnh, y học chẩn đoán…
So với các thuật toán truyền thống, deep learning mạnh vì khả năng tự học tầng tầng lớp lớp đặc trưng mà không phụ thuộc chuyên gia xây dựng feature phức tạp. Tuy nhiên nó cũng đặt ra thách thức lớn về sức mạnh xử lý — điều dẫn đến nhu cầu GPU mà CPU khó đáp ứng được.
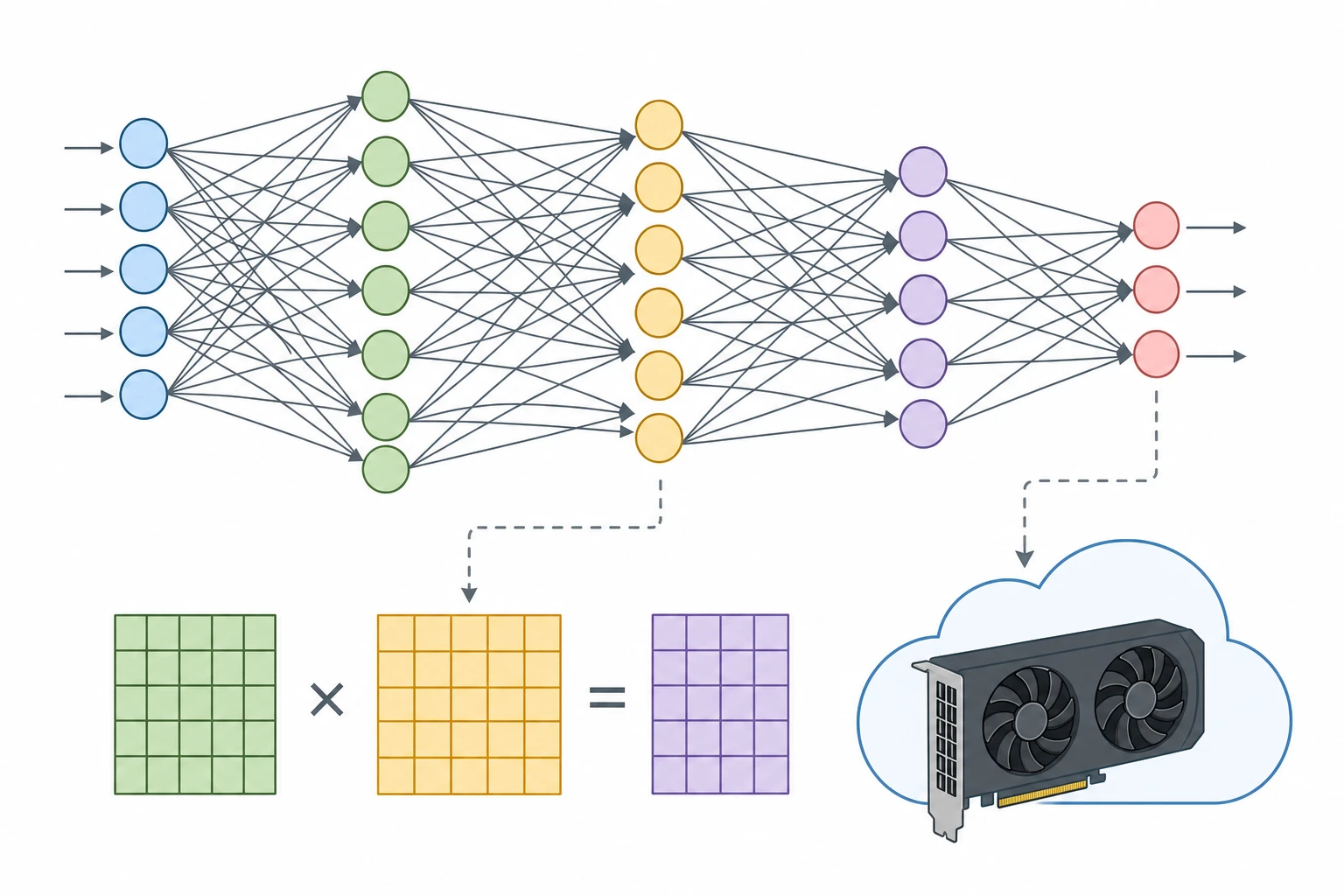
Vì sao deep learning lại cần dùng GPU?
Bạn có thể thắc mắc: các bài toán AI không phải đều có thể chạy trên CPU hay sao? Đúng là thế về lý thuyết, nhưng deep learning thực sự khai thác mạnh sức mạnh song song của GPU. Lý do:
- Khối lượng phép tính lớn: Mỗi bước huấn luyện mô hình là hàng triệu phép nhân, cộng ma trận liên tục giữa input và trọng số (matrix multiplications) — đúng sở trường của GPU.
- Kiến trúc song song hóa cao: GPU có hàng nghìn nhân xử lý nhỏ (CUDA core với Nvidia) vận hành đồng thời, tăng tốc tính toán song song gấp nhiều lần CPU vốn chỉ tối ưu cho tính toán tuần tự.
- Thư viện và phần mềm AI hiện đại: Các framework phổ biến (TensorFlow, PyTorch…) đều tối ưu mạnh cho GPU, đặc biệt các lệnh tensor, phép toán phổ biến trong deep learning.
Nếu chỉ dùng CPU, thời gian huấn luyện có thể kéo dài từ nhiều ngày thành vài tháng. Với GPU chuyên dụng như Nvidia A100/H100, bạn có thể giảm thời gian xuống chỉ còn vài giờ. Đó là lý do đa số các trung tâm AI lớn, nền tảng GPU Cloud Server đều trang bị GPU mạnh, đặc biệt cho các task deep learning.
So sánh CPU vs GPU trong huấn luyện deep learning
Khi xét hiệu suất thực tế, điểm khác biệt cốt lõi nằm ở hai yếu tố: số lượng lõi xử lý và băng thông bộ nhớ.
| Tiêu chí | CPU (Intel Xeon) | GPU (Nvidia H100) |
|---|---|---|
| Số lõi xử lý | 8–64 | >17.000 CUDA core |
| Băng thông RAM | 80–200 GB/s | >2 TB/s (HBM2e) |
| Thời gian huấn luyện | Chậm (có thể x100 lần) | Nhanh (chuẩn AI, accelerator) |
| Tiêu thụ điện | 60–350W | 400–700W |
- GPU vượt trội trong xử lý ma trận quy mô lớn và các phép toán song song
- CPU thích hợp hơn cho logic tuần tự, truy xuất file, xử lý tiền/xử lý sau mô hình
Do đó, hệ thống AI hiệu quả thường dùng cả CPU lẫn GPU: CPU lo phân phối dữ liệu, GPU tập trung tăng tốc training/inference. Trong thực tế vận hành, một điểm thường bị bỏ qua là quá trình copy dữ liệu giữa RAM (CPU) và VRAM (GPU) có thể trở thành “nút cổ chai” nếu không tối ưu hoá, nhất là với dataset lớn.
Những vấn đề khi dùng GPU cho deep learning
- Lắp đặt và bảo trì phức tạp: GPU hiệu năng cao toả nhiệt lớn, yêu cầu nguồn điện, tản nhiệt và firmware chuyên dụng (kỹ thuật rack, colocation hoặc GPU Cloud Server chuyên biệt).
- Giới hạn VRAM: Nếu mô hình vượt quá bộ nhớ GPU (VD: xử lý video 4K hoặc language model cực lớn), phải xử lý phân chia batch, multi-GPU hoặc offload một phần về CPU, ảnh hưởng hiệu năng.
- Hỗ trợ driver/phần mềm: Yêu cầu thiết lập chuẩn (Nvidia CUDA Toolkit, cuDNN, driver đồng bộ với framework AI) — người mới thường gặp lỗi không nhận GPU.Ví dụ một số lỗi thường gặp:
- Lỗi không nhận GPU trong TensorFlow:
Cách xử lý: Kiểm tra cài đặt CUDA, cuDNN, phiên bản driver Nvidia phải phù hợp với phiên bản framework.Could not find CUDA drivers on your machine, GPU will not be used. - Lỗi memory allocation failed:
Cách xử lý: Giảm batch size, kiểm tra VRAM, thử chia model hoặc sử dụng multi-GPU nếu có.ResourceExhaustedError: OOM when allocating tensor - Lỗi không đúng phiên bản PyTorch–CUDA:
Cách xử lý: Đồng bộ lại phiên bản PyTorch, driver Nvidia, CUDA toolkit cho đúng với GPU hardware.RuntimeError: CUDA error: invalid device function
- Lỗi không nhận GPU trong TensorFlow:
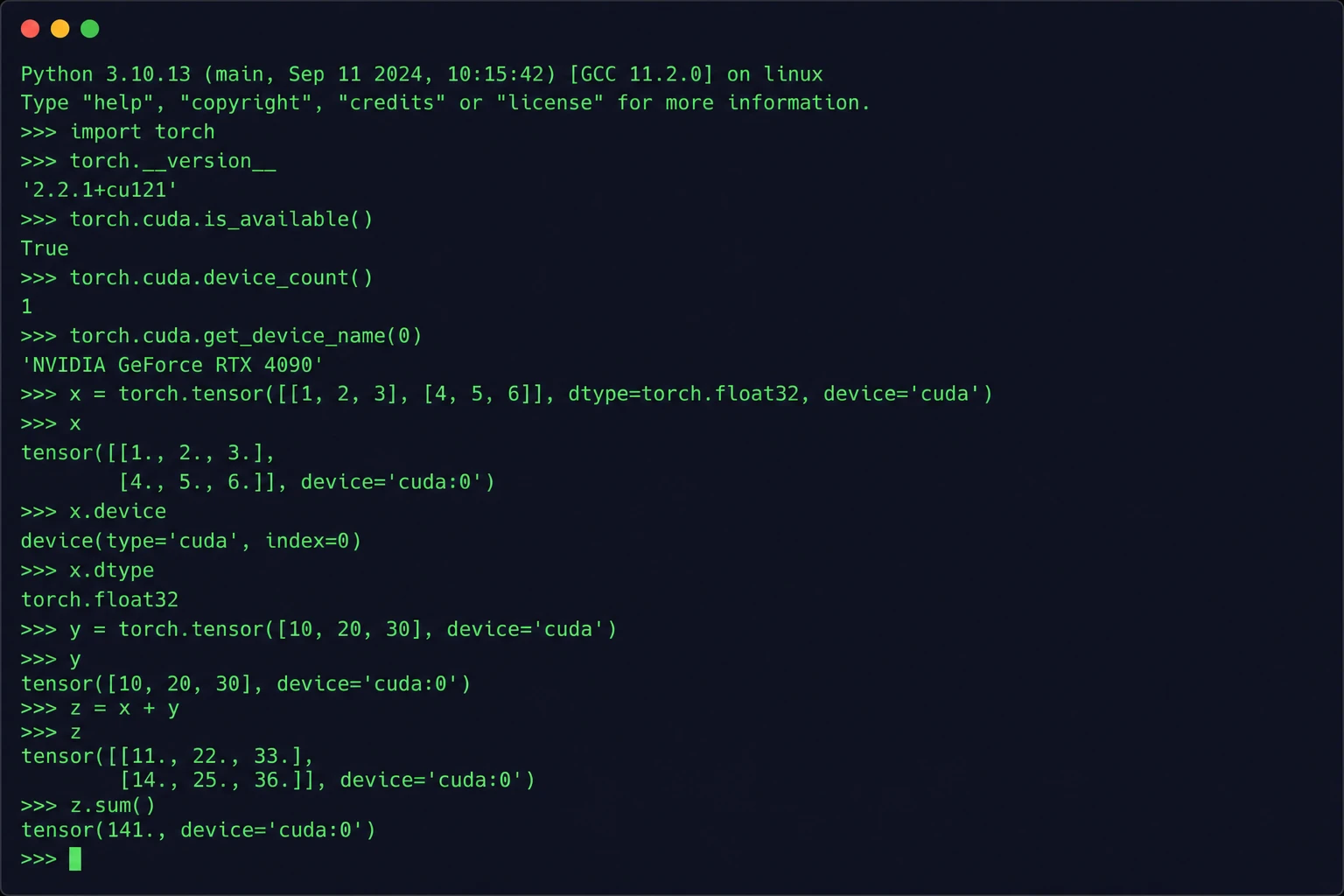
Làm sao biết hệ thống đã nhận GPU để huấn luyện deep learning?
import torch
torch.cuda.is_available()
Kết quả trả về True nghĩa là GPU đã sẵn sàng!
Dự đoán xu hướng: Deep learning – GPU sẽ đồng hành đến đâu?
Cuộc đua hiệu năng AI chưa có dấu hiệu chậm lại. GPU vẫn là “bộ xương sống” của deep learning tính đến 2026, đặc biệt cho các mô hình lớn (transformer, diffusion…) và những ứng dụng cần thời gian huấn luyện ngắn. Tuy vậy, thị trường cũng đang xuất hiện các lựa chọn phần cứng bổ sung như ASIC (Google TPU), FPGA chuyên AI — giúp tiết kiệm điện hơn trong một số trường hợp đặc biệt, nhưng tính linh hoạt vẫn thuộc về GPU.
Nếu workload của bạn ưu tiên inference quy mô nhỏ, latency thấp, hoặc cần mở rộng linh hoạt, dịch vụ như GPU Cloud Server sẽ là lựa chọn thực tế để thay thế đầu tư vật lý ban đầu.
Kết nối deep learning và hạ tầng Việt: Bí quyết chọn GPU hợp lý
- Chọn chỉ số FP16/TF32: Deep learning hiện đại tận dụng phép toán bán chính xác (FP16, TF32) để tăng tốc đáng kể. Trước khi đầu tư, nên kiểm tra GPU hỗ trợ chuẩn này (VD: Nvidia RTX 40, A100, H100…)
- Xem xét môi trường phát triển: Nếu chạy nhóm nghiên cứu, sandbox, build thử nghiệm — môi trường Cloud hoặc Private Cloud sẽ tối ưu chi phí, dễ cập nhật, không lo bảo trì phức tạp.
- Lựa chọn thông số hợp lý: Đừng chỉ nhìn VRAM, cần quan tâm băng thông bộ nhớ, bus PCIe/InfiniBand nếu chạy multi-GPU (huấn luyện phân tán).
- Lưu ý internal link: Nếu bài toán AI của bạn cần chạy liên tục, kết hợp với trao đổi dữ liệu lớn (hạ tầng truyền dẫn), nên cân nhắc Internet Leased Line hoặc truyền số liệu đáp ứng tốc độ đồng bộ giữa các node.
Bạn đang triển khai deep learning, băn khoăn chọn GPU, tối ưu môi trường xây dựng AI? Đội ngũ kỹ sư IDCViet nhiều kinh nghiệm thực chiến sẵn sàng đồng hành, giúp bạn đánh giá phương án GPU vật lý, cloud hay hybrid phù hợp cho dự án thực tế. Chi tiết: idcviet.vn | 0913320866 | [email protected]